RSECon22: Collaborating on the automation of research software publication with rich metadata
Oliver Bertuch (Forschungszentrum Jülich, ORCID), Stephan Druskat (German Aerospace Center (DLR), ORCID), Michael Meinel (German Aerospace Center (DLR), ORCID), Oliver Knodel (Helmholtz-Zentrum Dresden-Rossendorf (HZDR), ORCID), September 29, 2022
This post is being cross-posted on the Software Sustainability Institute blog.
Publishing your research software in a publication repository is the first step on the path to making your (research) software FAIR! But the publication of the software itself is not quite enough: To truly enable findability, accessibility and reproducibility, as well as making your software correctly citable and unlock credit for your work, your software publication must come with rich metadata to support these goals.
But where will this metadata come from? And who should compile and publish it? Will RSEs have to become metadata experts as well?
Project
HERMES (HElmholtz Rich MEtadata Software publication) is a project funded by the Helmholtz Metadata Collaboration that runs until June 2023.
We argue that source code repositories and connected platforms often already provide many useful metadata, even if they may be distributed over heterogeneous sources. Providing an open source software toolchain, we aim to help harvest these metadata, process and collate them, and prepare them for deposition in publication repositories.
The HERMES toolchain can be automated via continuous integration (CI) platforms, and publish the prepared metadata with or without the respective software artifacts, to cater for open, inner and closed source software alike. It can also feed the collated metadata back to source code repositories, or provide them in different formats for further reuse.
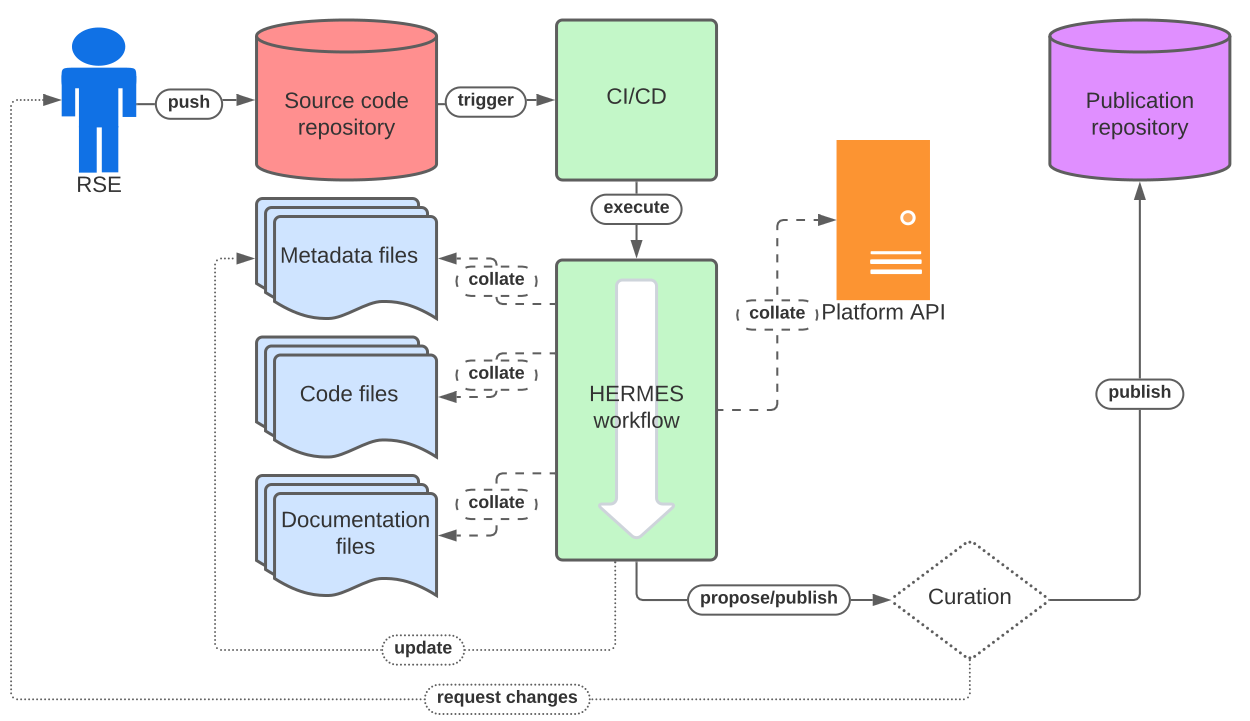
Figure: A high-level overview of the HERMES workflow to harvest, collate, publish and post-process software metadata. (Figure by the HERMES project, licensed under CC BY-4.0 Intl. Click on image to open in full size.)
By the end of the project, we aim to provide:
- the implementation of our workflow as a command-line interface,
- templates for continuous integration systems (GitHub Actions, GitLab CI, etc.) that wrap the workflow implementation,
- training materials,
- extensive documentation and
- proposals to update Helmholtz (and cross-institutional) policies on research software.
In addition, we are working to improve the “research software readiness” in publication repositories. This involves code contributions to Dataverse and InvenioRDM (see also our talk at the Dataverse Community Meeting 2022).
For more details of our concept, a summary of the current state of the art in software metadata and a comparison of our idea to existing projects, read our concept paper on arXiv.
Workshop
We think that the workflow tool and continuous integration templates will likely be used first and foremost by RSEs. To make sure we develop something that is actually useful, we wanted to share our first results with a larger audience from that specific community, test-drive the workflow, and gather feedback. A great place to do so was RSECon UK 2022 in Newcastle. At the conference, we presented HERMES in a talk (slides, recording forthcoming), and hosted the workshop that we report on here.
The workshop ran in two 90 minutes sessions, a plenary session presenting and discussing the HERMES concept and participants’ experiences with software publication, and a session where we worked together with participants in different groups. The audience consisted of RSEs and community leaders.
First Session: Experiences
The first session outlined the agenda of the workshop, introduced the topic of software publication and explained our concept. We then collected the audience’s experiences with the current state of creating software publications.
Experiences with software publication were mixed. The audience agreed on the necessity of software publications as an enabling source for sustainability, reproducibility, academic credit and FAIR research software.
Some of the issues we heard about were the arduous manual work that was needed to publish software, as well as depositing metadata cleanly, especially when there are a lot of software authors for a publication. The notion of software authorship in itself also seems to be problematic, as - in contrast to journal publications - no clear guidelines exist for what constitutes authorship. Furthermore, it is tricky to preserve the original meaning of metadata when the respective metadata fields in the metadata source and the publication target platform have different semantics. And finally, gathering together metadata from different sources, and working with different licenses for the same research object, is still hard.
Some participants already used existing publication workflows, such as the GitHub Zenodo integration. Here, we highlighted the key differences between the GitHub Zenodo approach (where metadata is pulled from a source code repository) and our HERMES concept (where we actively push metadata to a publication repository). But some software also remains unpublished based on a feeling that “my software is not ready”, or a reluctance or lack of resources to provide maintenance and support. In these cases, metadata-only (yet FAIR) publications can provide an alternative.
The session wrapped up with the formation of breakout groups and general feedback.
Second Session: Breakouts
After the break we continued collaborating in four breakout groups.
One group set out to discuss “mixed content” deposits, i.e., publications from repositories that contain more than one thing. This could be more than one software unit (package, script or similar), but also a mixture of software, data, publications, etc. The Carpentries’ lessons repositories, for example, may contain the lesson sources, as well as code and requirements metadata. Early on in the HERMES project, we discussed internally how to deal with these use cases. We considered prescribing what we then perceived as good practice, namely strictly separating different types within a repository over different deposits. This way, HERMES would set requirements for repositories, e.g., software source code would have to live in a separate directory in the repository.
However, the discussion in this group clearly showed that this would not work in the real world, and would be overly prescriptive, keeping potential users from leveraging the positive impact of the HERMES workflow on their work. Instead, we found that the workflow implementation should be able to work with whatever users supply, including mixed content repositories, and what the recent ARDC National Agenda for Research Software in Australia called “analysis code”: software source code that is tightly coupled with data that often lives in the same repository.
Due to their heterogeneous nature, working with these kinds of repositories will likely require HERMES to provide detailed feedback, and elicit further user input on what metadata the workflow has identified, and how it pertains to the contents of the repository. This will specifically be the case with repositories that include content under different licenses. We therefore identified the need for a way to give feedback and ask for more input, and discussed the implementation of bots that can do this in a user-friendly way in issues and/or pull requests. At the same time, we identified the need for the workflow to act “defensively” and better ask again than permit bad metadata to end up in publication repositories. Finally, specific solutions for mixed content deposits exist, such as RO-Crate, and HERMES may leverage these to provide “native” support for mixed content deposits.
Another group created a proof-of-concept Github Workflow to demonstrate how the HERMES workflow can be run from a CI job. It currently lives in a feature branch in our GitHub repository. Feel free to have a look at it for a peek preview on how you will be able to use HERMES in your own projects.
Two further groups decided to join up, as they were working on overlapping topics. Going through the documentation, they installed the HERMES workflow tool locally on their machines and tried to run it. In the process, they also looked at the current codebase. We also learned that we should offer user documentation in addition to our developer documentation at this stage of the project in order to show how future RSEs interact with HERMES. Problems and issues that they discovered were documented in a number of issues in our workflow issue tracker or were fixed in place.
Conclusion
We thank all workshop participants for the discussion of and feedback on our concept and ideas, for giving our early workflow implementation a try, improving the documentation, and opening lots of issues that highlighted existing flaws in the work-as-is. We’re looking forward to fixing them and making our tooling more useful for you!
We work on HERMES in the open, and are looking forward to engaging further with the community. If you want to contribute, please feel free to try our workflow on GitHub and leave feedback in issues, or reach out to us directly!