Recap: Workshop Let's talk FAIR for research software at SE2022
Martin Stoffers, Tobias Schlauch, René Caspart, Alexander Struck, June 2, 2022
In our workshop at SE2022 we discussed practices in and handling of research software development and how this relates to the FAIR principles for Research Software [Lamprecht2020, Katz2021]. In the first part of the workshop we introduced the three topics, “Foundations of Research Software Publication”, “FAIR in HPC” and, “Findable Research Software”. The second part of the workshop was organized as a World Café where we discussed these topics in three sessions. In this blog post we want to summarize the findings of these sessions and of the workshop as a whole.
Foundations of Research Software Publication
The first session focused on subjects covered in the HIFIS workshop “Foundations of Research Software Publication”. In the first part, we asked what new subjects should be addressed in a new or extended workshop version. Here we uncovered three more subjects that may be good candidates to improve the workshop’s content. These subjects are “Maintenance and life cycle management for Research Software”, “Contributions and Community” and, “When not to write your own software”. All three subjects are strongly related to the core values of the FAIR principles. In addition, the provided feedback suggested that the current workshop title might be very appealing to research software engineers but might not raise interest in other intended groups such as PhD candidates or scientists. Beside investigating this issue further, one solution might be to host dedicated workshops with different titles but mostly similar content. We also concluded that our workshop could benefit from a more modular concept were subjects can be interchanged depending on the required skills of the audience.
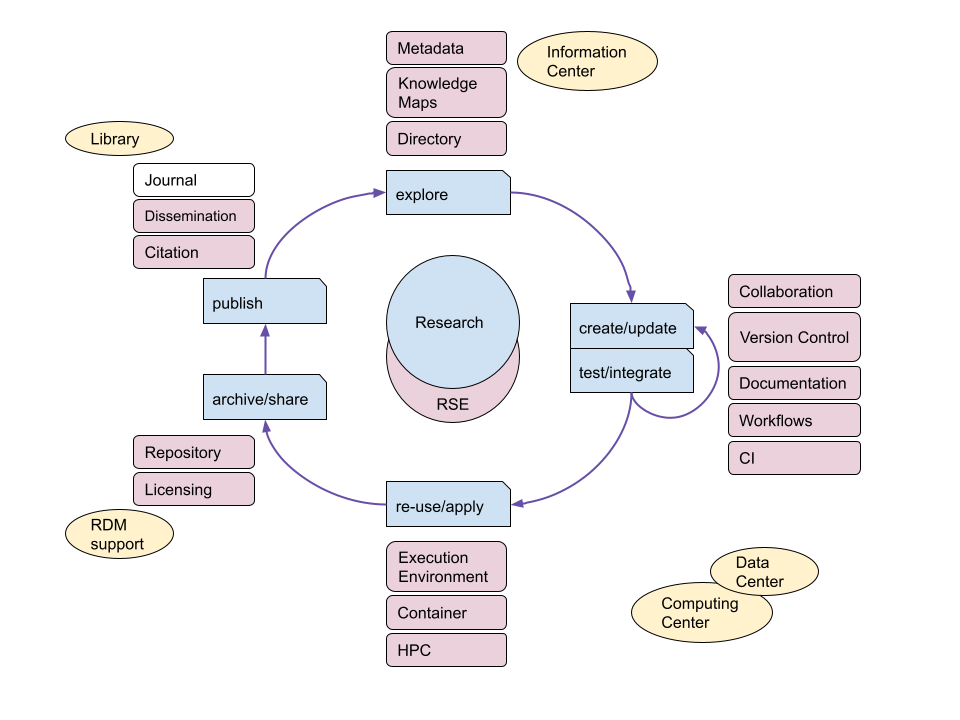 |
|---|
| Life cycle management in Research Software Engineering. Credit: Stephan Janosch |
In the second part, we asked what specific topics current subjects such as, “Documentation”, “Licenses”, “Citations/Findability”, and “Release management/Publication” and newly suggested subjects could benefit from. Within the subject “Release management”, teaching the use and importance of standardized installations processes was raised. In the subject of “When not to write your own software” the importance to teach tools and techniques to select third-party software and the aspect of findability for research software were discussed. Especially the latter was further discussed in our session of “Findable Research Software”. Based on the feedback, the subject of “Contributions and Community” should be extended to cover topics like “Code of Conducts” or “Contributor Agreements” in future workshops. Questions raised were: “How to handle contributions?” or “How to encourage contributions for community building?”. Especially “Contributor Agreements” was reported as topic with high uncertainties for single researchers or RSEs with respect to legal frameworks and rules within research organisations. Lastly, the subject of “Maintenance / Life Cycle Management” was actively discussed across groups. It was mostly perceived as a big challenge in research software engineering. Participants mentioned questions about long-term code ownership, missing funding for maintenance, and maintaining of software with feature creep [Elliott2007] as challenges. The complexity of life cycle management was put into perspective using a drawing created by Stephan Janosch, which outlines important aspects of the whole process. One particular problem mentioned in this context was that it is often easier to use and cite older releases instead of adapting code in newer releases. One open question raised from this discussion was: “How do we create incentives for scientists to help maintain the software they rely on?”. We think life cycle management is an important topic that needs to be coverd in future workshops. However, further research on life cycle mangement in research software engineering is needed before we can provide sufficient training material on this topic.
FAIR in HPC
The second session covered the topic FAIR in HPC, with a specific focus on Accessibility. Together with the participants we discussed experiences and ideas related to the usage of HPC clusters in research software engineering, but also research in general. In the first part, we asked the participants about their experiences with using HPC systems for their work. A commonly raised topic was the issue of different setups at different HPC systems. In addition, restrictions in the accessibility of Internet resources and data transfer were mentioned. Researchers experience increasingly more difficulties in including the HPC systems in custom workflows, e.g. due to tightening of security and 2FA, resulting in an stronger dependence on provided services. In the second part, we asked the participants about their ideas for either improving existing infrastructures and services or new, not yet widely available, services to support their everyday work. The participants noted that an increased homogenization of HPC clusters would be apprecicated to improve the Interoperability for different clusters. Specifically for RSEs, a better integration with common tools, such as continous integration, and related workflow management was voiced. Going beyond the demands specific to the software development aspect of RSE, general workflow-management tools and specifically a better integration and support for electronic lab notebooks (ELN) was also voiced. In the context of FAIR, ELNs play an important role, as they allow researchers to more easily and efficiently keep track of their work and results. Such information may ease Reusability.
Findable Research Software
Why did you (not) search for software?
We entered the world cafe with this two-fold question after a short introduction of the idea. Among the reasons for people actively searching for software, we want to highlight the following:
- reduce the amount of complexity to manage
- speed up development by reusing existing implementations of certain algorithms
- need to use an ‘industry standard’ solution
- assuming 3rd-party solutions may have better quality than what oneself could produce
- for comparison purposes and ‘inspiration’
That spun off discussions with heavy opinions on when to not search for software. Most prominent arguments were:
- one’s own tasks are often considered to be too specific to expect existing solutions (This is in line with Marshall2006 who found that researchers do not search for code when they assume there is none.)
- “Not-invented-here” syndrome and other forms of ‘software development narcissism’
- ‘intellectual curiosity’ to develop/reimplement something on your own for the learning experience
- expectation to have more control over a software product if external dependencies are reduced
- in some cases (existing) software need to be ported into an environment, so there needs to be a rewrite/port
- a self-created program is assumed to be available much quicker than searching for (and maybe evaluating) existing solutions
- in certain research disciplines, code sharing is unpopular, so searching for code was seen as ‘a waste of time’
Studies and policies related to software publishing [Akhmerov2021, Hucka2018, al Noamany2018, Howison2015] document these and some other reasons why code may not be shared.
How and where did you search?
The actual search for software was conducted as reported in previous papers, e.g. Howison2015:
- colleagues, GitHub and Google are most popular
- some researchers also follow references and URLs in papers and on conferences
- field specific registries exist but are only rarely used
- private in-house GitLab instances
There was agreement, that an evaluatory ‘trial & error’ phase for found software is required. We hope that certain other locations, like language-specific repositories, e.g. CRAN for R, are also in use although not mentioned.
How to improve Findability?
We also asked the participants to populate a wishlist that would improve the(ir) current situation. From the wide range of suggestions, a few stand out:
- have an institutional repository to see what has been done locally
- global ‘curated software catalog’ (some disciplinary repos like swMATH.org exist)
- make ‘public money – public code’ mandatory in some funding schemes (which is assumed to improve findability)
- some software engineers wish for platforms where code could be uploaded and benchmarked against competing solutions (which is not a publishing platform and may not improve Findability)
- software should be accessible, citable and, most importantly, also cited [Smith2016]
- the paper review process should include data and software review (which may require additional resources)
- pre-registration (similar to medical research) has been suggested to formalize and open up the software solution development and implementation.
Findability Conclusion
While the number of participants is not representative for Research Software Engineering, the shared notions reflect commonly accepted views and strengthen conclusions of recent papers. Several stakeholders have an interest in improved findability of software and some act on it. Examples include the FAIR for Research Software [FAIR4RS] working group at RDA.
Concluding Thoughts
The audience appreciated the workshop topics and the format. As organizers we received valuable input in all three sessions. In particular, we were able to map some activities to FAIR principles and raise awareness for many of its aspects. We recommend this format and venue to gather input for your projects. A future de-RSE conference will also be a promising platform.
Further Reading
Anna-Lena Lamprecht et al., “Towards FAIR Principles for Research Software,” ed. Paul Groth, Paul Groth, and Michel Dumontier, Data Science 3, no. 1 (June 12, 2020): 37–59, doi: 10.3233/DS-190026. https://doi.org/10.3233/DS-190026.
Daniel S. Katz, Morane Gruenpeter, and Tom Honeyman, “Taking a Fresh Look at FAIR for Research Software,” Patterns 2, no. 3 (March 2021): doi: 10.1016/j.patter.2021.100222, https://doi.org/10.1016/j.patter.2021.100222.
Ruijter, Maria Cruz, Paula Martinez- Lavanchy, Mark Schenk, Margot Spaargaren, and Marta Teperek (2021). TU Delft Research Software Policy. en. doi: 10.5281/ZENODO.4629662. url: https://zenodo.org/record/4629662.
B. Elliott, “Anything is possible: Managing feature creep in an innovation rich environment,” 2007 IEEE International Engineering Management Conference, 2007, pp. 304-307, doi: 10.1109/IEMC.2007.5235049. url: https://doi.org/10.1109/IEMC.2007.5235049.
AlNoamany, Yasmin and John A. Borghi (Sept. 2018). “Towards computational repro- ducibility: researcher perspectives on the use and sharing of software”. In: PeerJ Com- puter Science 4, e163. doi: 10.7717/peerj-cs.163. url: https://doi.org/10.7717/peerj-cs.163.
Howison, James and Julia Bullard (May 2015). “Software in the scientific literature: Problems with seeing, finding, and using software mentioned in the biology literature”. In: Journal of the Association for Information Science and Technology 67.9, pp. 2137– 2155. doi: 10.1002/asi.23538. url: https://doi.org/10.1002/asi.23538.
Hucka, Michael and Matthew J. Graham (July 2018). “Software search is not a science, even among scientists: A survey of how scientists and engineers find software”. In: Journal of Systems and Software 141, pp. 171–191. doi: 10.1016/j.jss.2018.03.047. url: https://doi.org/10.1016/j.jss.2018.03.047.
Marshall, James J., Steve Olding, Robert E. Wolfe, and Victor E. Delnore (2006). “Soft- ware Reuse Within the Earth Science Community”. In: Proceedings IGARSS 2006 - 2006 IEEE International Geoscience and Remote Sensing Symposium; July 31, 2006 - August 04, 2006; Denver, CO; United States. url: https://ntrs.nasa.gov/search.jsp?R=20060027793.
Smith, Arfon M., Daniel S. Katz, and Kyle E. Niemeyer and (2016). “Software citation principles”. In: PeerJ Computer Science 2, e86. doi: 10.7717/peerj-cs.86. url: https://doi.org/10.7717/peerj-cs.86.